I was recently involved in an issue in an evnironment that started out looking like a simple SSL certificate replacement and ended with multiple hours of troubleshooting with GSS and redeployment of vSphere Replication. Fun times, right?!
Let’s take a step back. This customer has a straight forward environment. Two physical sites, one vCenter Server and external PSC per site (6.5) in the same single sign on domain. Each site had one vSphere replication appliance and one Site Recovery Manager Server, version 8.1.2.8325 Build 13095593 to be exact.
The PSC and vCenter Servers had trusted custom SSL certificates installed for their Machine_SSL certificates, as per the VMware preferred “hybrid” SSL model for the appliances. These certificates were coming up for renewal which was planned and executed. After the SSL certificate replacement, we went to reregister the vSphere Replication appliances, but immediately ran in to an odd error code:
BAD EXIT CODE:1
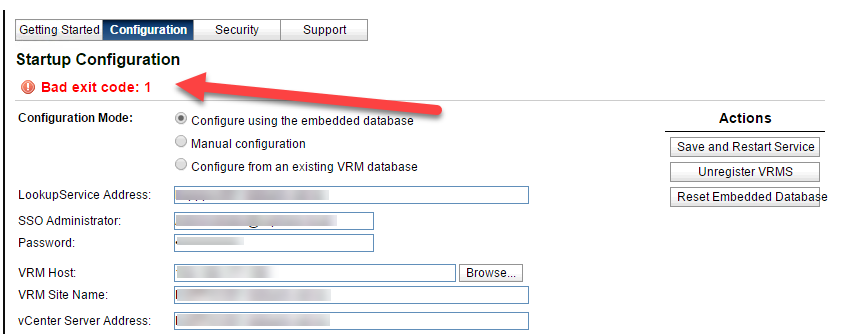
A quick look on my favourite search engine directed me to the following KB which seemed to be exactly my issue. I followed the instructions to power off and power on the appliance in site 1 and it worked well and I was able to successfully reregister vSphere replication.
The vSphere Replication appliance in site 2, on the other hand, would not play ball and was akin to a boxing match with a Kangaroo - not an enjoyable experience. After trying the power off / power on several times, I was still receiving the same Exit Code. I started to dig in to the vSphere Replication logs and couldn’t find a lot of helpful information, other than confirmation that the connection to the vCenter Server was erroring:
java.util.concurrent.ExecutionException: com.vmware.vim.vmomi.client.exception.SslException: com.vmware.vim.vmomi.core.exception.CertificateValidationException: Thumbprint mismatch
at com.vmware.jvsl.sessions.net.impl.PersistentConnection.start(PersistentConnection.java:159)
at com.vmware.jvsl.sessions.net.impl.vc.ServerViewImpl.start(ServerViewImpl.java:85)
at com.vmware.jvsl.sessions.net.impl.vc.ServerImpl.getVcUserView(ServerImpl.java:150)
at com.vmware.hms.security.authentication.SessionManagerImpl.checkCurrentSessionHealth(SessionManagerImpl.java:112)
at sun.reflect.GeneratedMethodAccessor1396.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
I dropped the issue and log bundles with GSS in the hope they would point me to a KB or known issue that I was missing. Unfortunately, this wasn’t the case. Initially they asked me to redeploy the appliance, which isn’t trivial in this environment nor was it something I was happy to proceed down the path of for something as simple as an upstream SSL certificate change.
To cut a long story short, after a lot of troubleshooting which included checking the SSL thumbprints on the vCenter Servers, trying the Power off / on of vSphere Rep from both HTML and flash web clients, resetting the SSL certificate on the vSphere Rep appliance to self signed, attempting to reset the embedded database, among many other tests and log re-uploads, we got absolutely nowhere.
There is a file named ovfEnv.xml, located at /opt/vmware/etc/vami. This file contains details about the configuration of the vSphere replication appliance, and this is the file that is attempted to be regenerated by a power off / power on of the appliance, in the event of it being missing or corrupted. The file was getting flagged as missing on boot up and was being restore from a .bkp file on each boot:
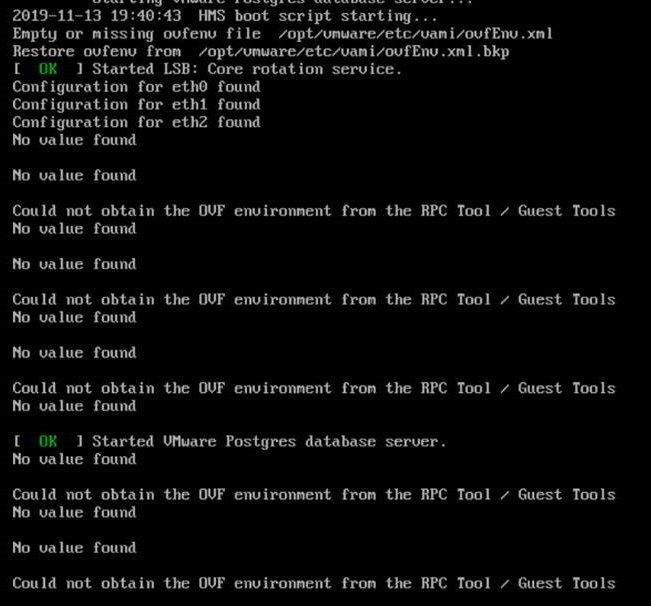
Unfortunately, this exhausted the troubleshooting and without escalating to engineering, led us all the way back to the option of redeploying the vSphere Replication appliance as a resolution. While this did work out OK in the end, it isn’t something I would be happy to be doing in an environment that had a large number of replications configured, caused by something as trivial as a SSL certificate change on the PSC and VC that the appliance connects to. I asked the GSS engineer to send this through in case it happened to be a reproducable issue that engineering can implement a fix for in the future rather than a sledgehammer approach of an appliance redeployment.